
Ml training on mac
Introduction
If you work in tech, you may have a Mac Book Pro and not a desktop computer.
This means that you have no access to a Nvidia GPU on your local setup. This can be an issue when wanting to train ML model.
In this blog post, we are going to see that :
- 💻 - You can train small model on a M1 GPU
- 🏃 - How fast this training is against a desktop RTX 4080
- 🏎️ - Check the performance difference of the latest M3 Max against Nvidia GPU
Train on a M1 Mac using your GPU
It can come as a surprise but this is actually very simple to use your mac GPU for faster training. The GPU framework is called 🤘 Metal 🤘.
import torch
if torch.backends.mps.is_available():
mps_device = torch.device("mps")
x = torch.ones(1, device=mps_device)
print (x)
else:
print ("MPS device not found.")
If this piece of code succeeds, your are good to go !
How faster is it ?
For that question, we will use a training heavy piece of code. You can find the reference here.
The code uses no data loading to avoid any kind of cpu limitation.
To make this benchmark, we will use other point of comparison :
- A cpu only run
- the M1 gpu run
- a desktop RTX 4080 run
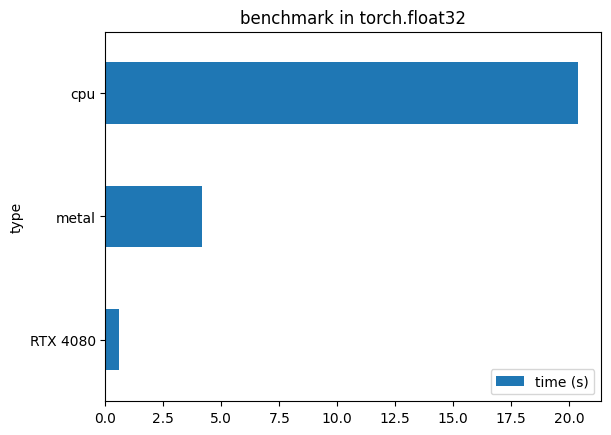
You can obsere the duration of the benchmark between the different devices
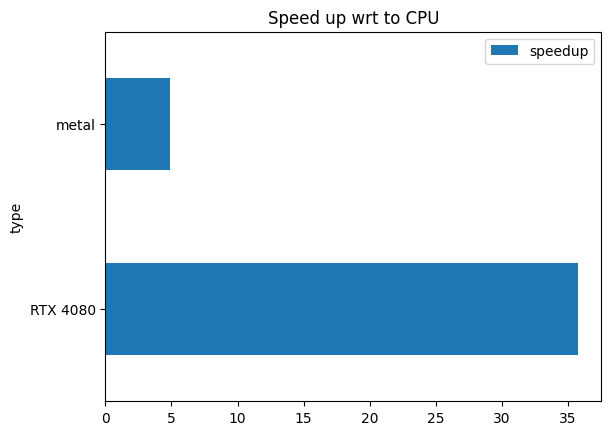
By checking speed ups, things are more obvious.
Does everything works the same ?
Not really 😿.
Some operators are not available, like the convenient torch.amp.autocast, which fails with metal.
However, it does not mean you can’t have half precision with Metal, but you will have to implement it yourself.
If you cast yourself all the models and input tensors, you can get a small speed-up.
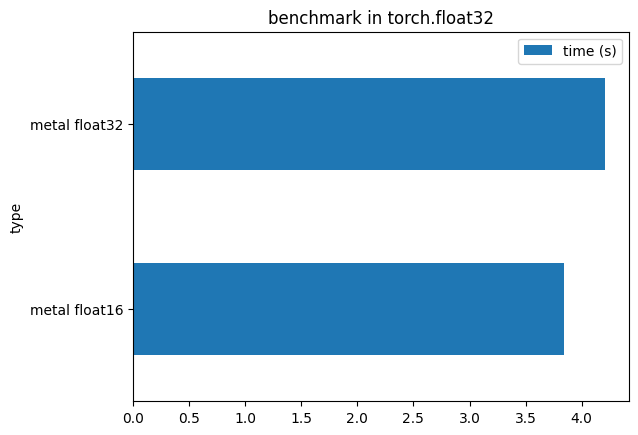
An interesting check is also the difference of gain in smaller precision. Look at the next chart :
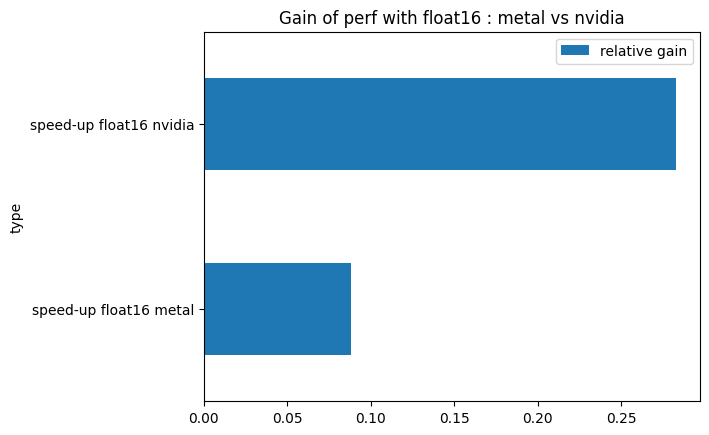
On Nvidia latest GPU gen, you get a large speed up when using float16, wheras Metal does not show such a large improvement.
But the comparison is not a fair one
I admit it. The M1 mac can’t have the performance of an power-hungry desktop GPU. Also the M1 is not the M3 max according to multiple benchmarks.
But in order to make up your mind, i have found the following list of ressources :
- LLM inference benchmarking : the M3 Max wins
- Deep learning training benchmarking : all the M series are loosing against Nvidia GPUs
- Generalist benchmark : A laptop 4090 is slightly above a M3 max
In conclusion :
- You want to run inference of Llama-70B, go for a M3 Max with a large amount of Unified RAM
- For everything else that requires training, go for a recent nvidia card