
Find your online clone
Introduction
Have you ever felt that someone on TV looks exactly like that friend from high school ?
If you are from this breed of people, I have what you need. The tool that will do this for you.
With a single picture of your face Sozy will search through a database of celebrity faces to find the closest match.
I later came across twinstrangers.com and found they had the same goal.
Getting the data
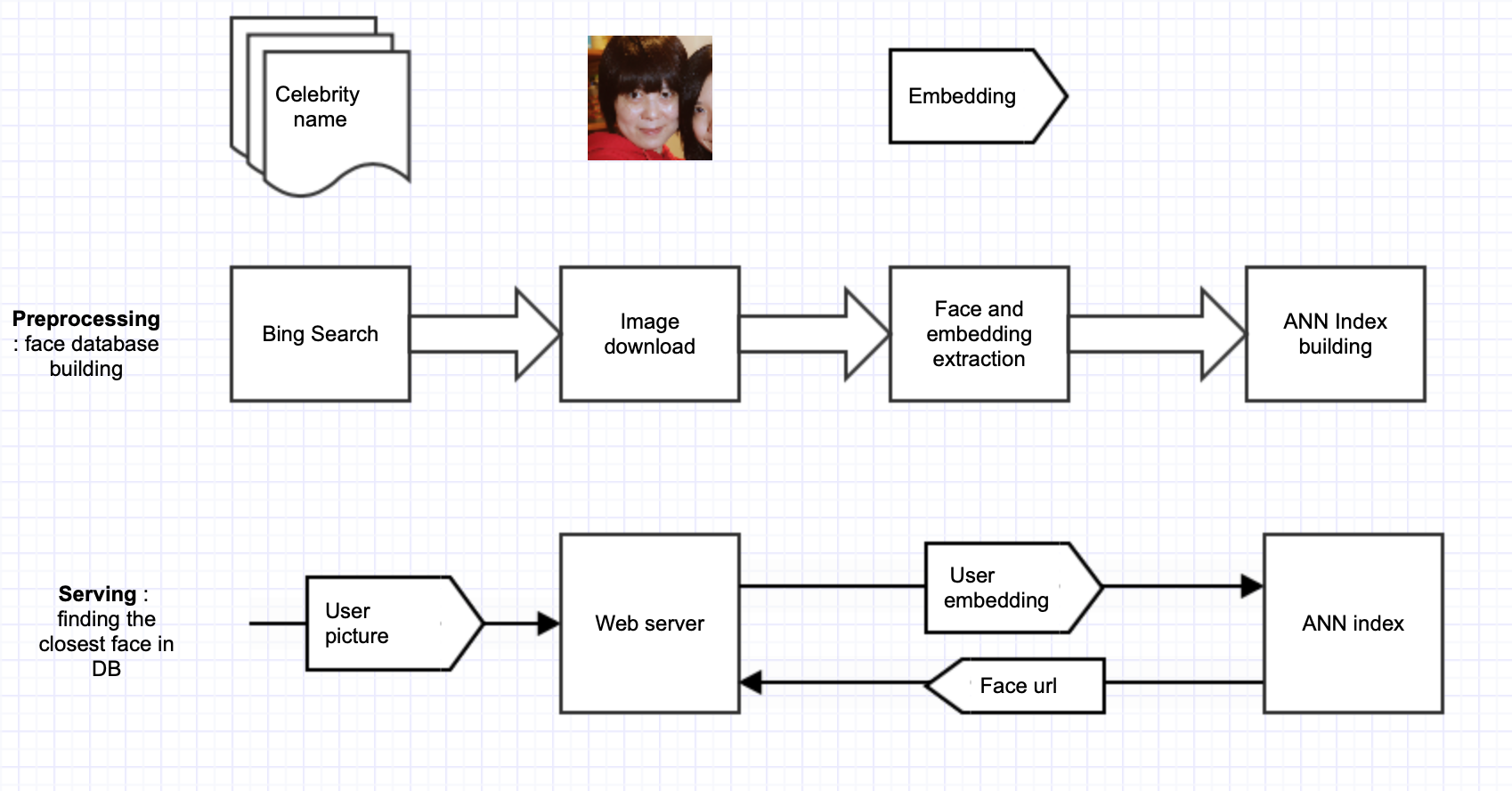
Collecting faces
We need 4 main steps in order to get those faces
- Get names of celebrities
- Find pictures of these celebrities on the internet
- Download the pics
- Extract face embeddings from a neural network
They can be achieved with the following solutions :
- To get names, we can get it from website like this one
- Once names are ready, we can use a bing scraper to get a set of images
- To download images, I used a customised wget python
- Finally to get face embeddings, there is the very handy project face-recognition/
Easy right ?
Running it to scale
The great advantage of python is that everything has already been developped by someone somewhere. But when you glue everything together, you still need to think about how to it properly.
In python, multi threading is complicated. However you can use multiprocessing. But there were a few rules and tricks to follow :
- Use queues to pass tasks between the different steps
from multiprocessing import Queue, q_in_url = Queue(maxsize=1500)These queues are expected as input and output of all steps
def download_worker(q_in, q_out): while True: url = q_in.get(block=True, timeout=60) try: local_path = download(url) while q_out.full(): time.sleep(0.5) q_out.put(";".join([url, local_path])) except Exception as e: print(e) -
You need to watch idle/dead workers. There is no direct way to add a timeout in the process being launched. So this has to come from inside the job and be properly wrpaeed in try/except blocs
- Gpu workers are different
import multiprocessing as mp mp.set_start_method('forkserver', force=True)They need to be spawned differently and you should be very careful on the max gpu memory consumed. 1 worker was the max for me.
Other pains
-
Scrapper get forbidden solution : Add a random user-agent
-
Downloader hanging Add a timeout in requests settings
Serving the doppelganger faces
Tricks to have a lightweight app
1 million faces requires a good backend in order to serve this volume. But this is not required as we can store the url and the face location only.
So the data stored is only :
- original url
- face location
- embedding vector (size 128)
It is also possible to apply a crop on the html displying the url
<img id="example-element" src=""
style="object-position: -px -px;object-fit: none; width: px; height: px">
This snippet is extracted from the jinja template used to display results.
This way we don’t need to store more than an url and a few numbers for the pictures.
Approximate nearest neighbour (aka ANN)
After a long search among all the possible libs, I settled on Annoy to get an approximate nearest neighbour engine.
It is competitive enough and works out of the box.
The web app
The web app is relatively simple :
- A single page asks for the picture
- On the backend side, once the picture is received, it is processed the same way than the scrapped images
- The resulting embedding is used as a query for the ANN and returns a set of indexes corresponding to the faces close enough.
This part was designed using Fast API. It was indeed a huge boost of productivity compared to Flask. I highly recommend it.
Aftermath
All the code can be found on this github repo
Results were however a bit disspointing even with a reasonbale amount of faces scrapped. You don’t find a doppelganger of anyone with just a few pictures of a large set of celebrities.
The face model is also a bit racist (like most ml models unfortunatelly) making it difficult to open for the public.
And I also happened to kill my desktop gpu in the process of extracting embeddings from all the face :(.