
Feature visualisation : the basics
The basic idea behind feature visualisation is to find an image that maximize the value of a given neuron in a neural network.
How does it work ?
We initially train a neural network function to recognize concepts (usually ImageNet with 1000 object classes), let’s say AlexNet.
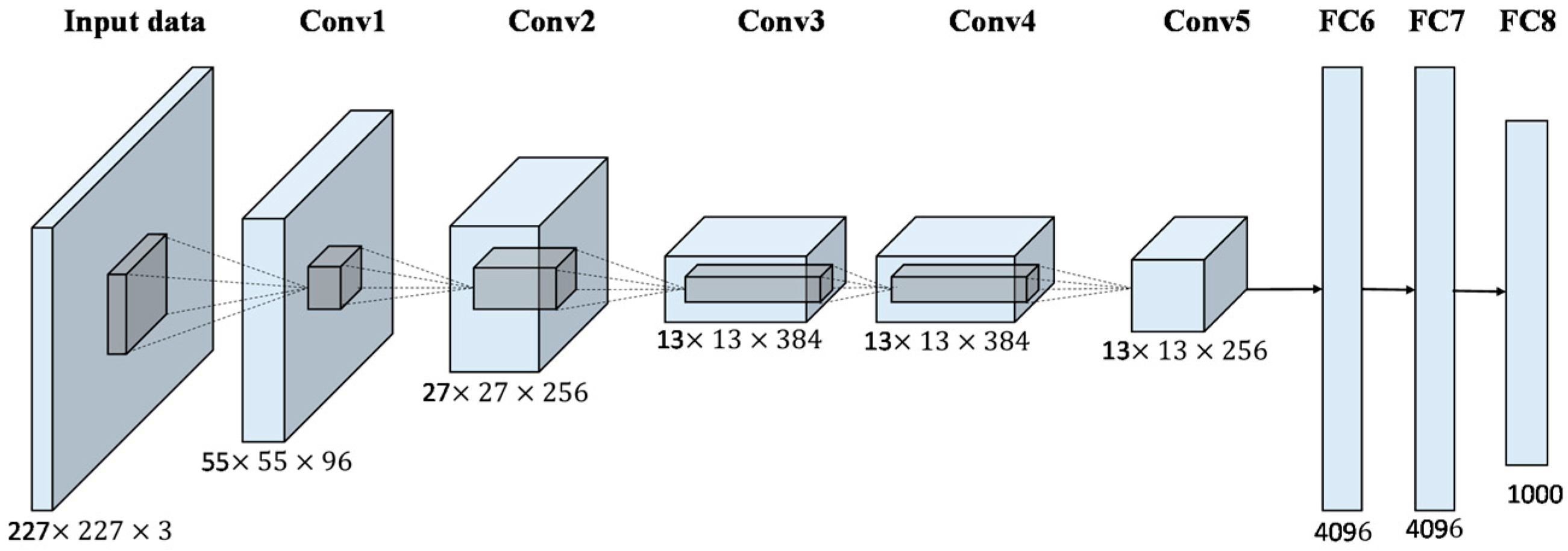
In this neural network, we want to know what activates a specific layer, let’s say Conv5. We will try to find an image I that maximize the norm of this layer.
Our loss is going to be something like :
We use back-propagation to have an image that will gradually get a lower score. The neural network is differentiable and thus we can get a clean gradient to update our image.
Depending on the network, this gives more or less interesting pics.
What does it look like ?
This is where things get complicated. With basic optimization, we mostly get noise :
That’s where our regularization(I) comes into play. We need it to remove the high frequency noise and keep only the image structure. To do so, we use total varialtion loss.
With the right lambda, we can still have the structure and remove most of the noise.
It looks different from network to network and layer to layer, but we can get satisfying results.
Let’s see some examples
AlexNet, different layers



Last layer, VGG16

As we can see, the networks generate totally different img. But we can recognize some things on last layer (close to the object prediction of ImageNet like frog).