
Easy dataset scrapping
Introduction
Web scraping, or the automated extraction of data from websites, can be a powerful tool to create a dataset for a new ML application.
In this tutorial, we’ll explore how to use Python and BeautifulSoup to scrape a website and extract useful data.
We will use the website https://www.svgrepo.com/ as an example. It claims having 500k SVG, it will be a good start for our new dataset.
Disclaimer : Please be considerate when scrapping. Don’t send 1000 scrappers on a small website and make it crash.
1 - Scouting for information location
The first step is to inspect the HTML code to find where the data you want is located. In our case, we want to find the all SVG urls to download them later.
1-a) Website structure : Index page
We can check how the website is organised in order to be sure to find all the data of interest.
We notice that we can find all the SVG collections using the following url https://www.svgrepo.com/collections/all/{index}
These pages offer multiple collections of SVGs.
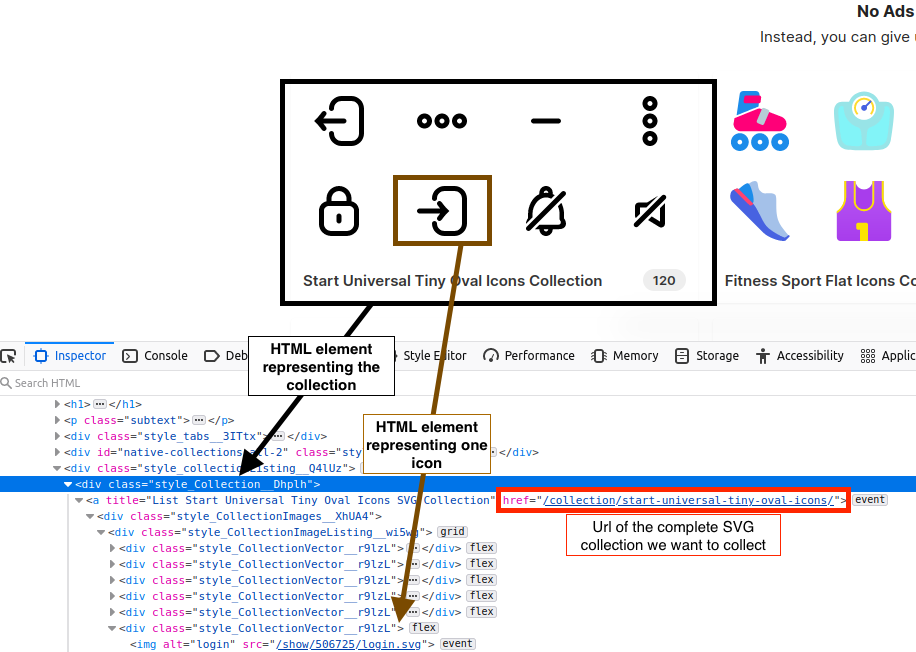
In this screen capture, we can see how we found the name of the class used as a container for the collection.
1-b) Website structure : collection page
With the link collected in the previous section, we can now hunt for the image links.
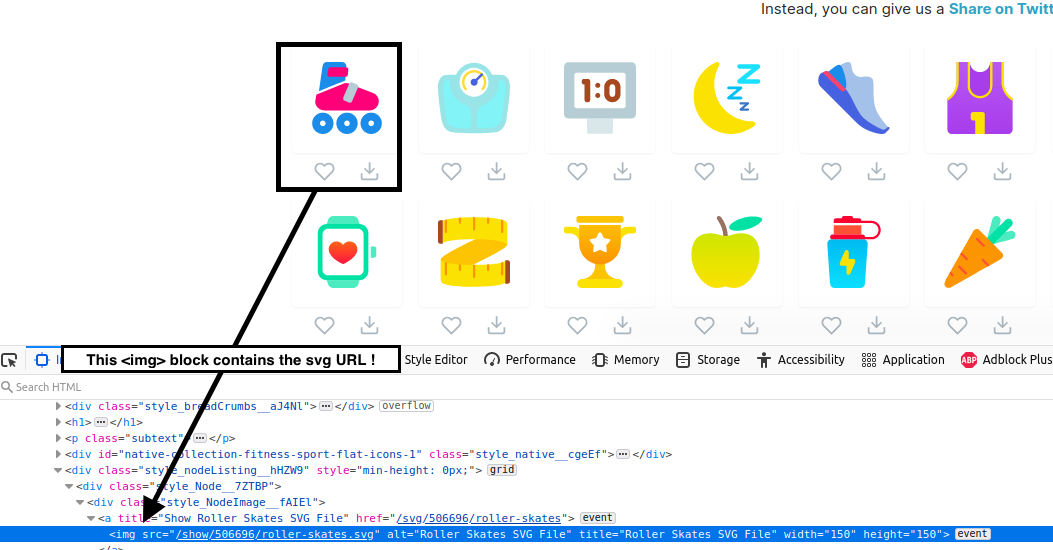
This screen capture shows we could go for either the <img> tag or go for the right class name as before.
1-c) Website structure : image tags
Finally, we can also go through the image detail page given the previous page.
On this page, we can find tags useful for ML usage.
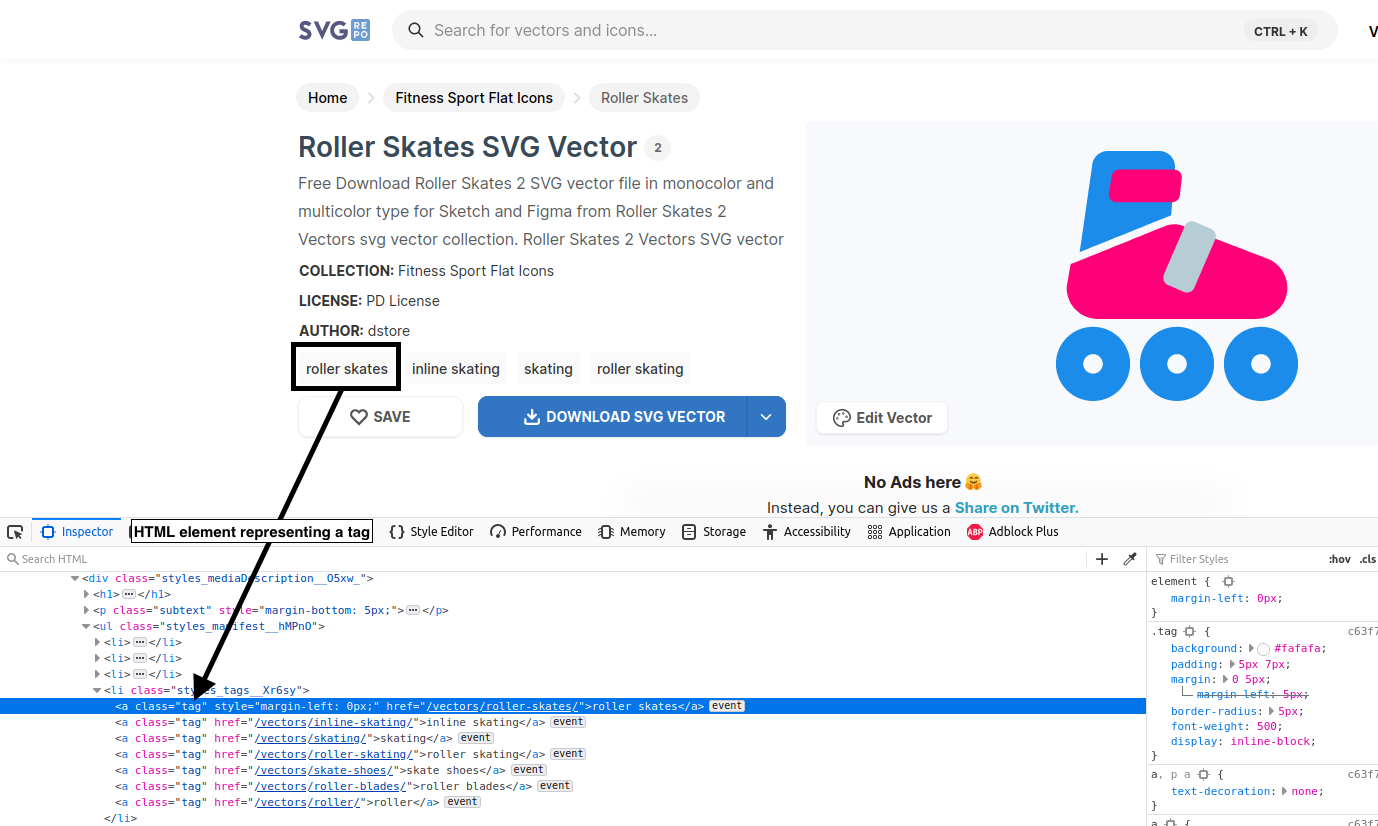
On this screenshot, another example of how to find the right field. Here, a query on the <a class=tag> will do.
2 - The actual scrapping
2-a) The basics on BeautifulSoup
We will focus on a single capability : the find function.
The find() function in BeautifulSoup is used to search for the first occurrence of a particular HTML element in a document.
Here’s an example of how to use find() to extract the title of a movie from an HTML document:
from bs4 import BeautifulSoup
import requests
# Make a request to the IMDb Top 250 page
url = 'https://www.imdb.com/chart/top'
response = requests.get(url)
# Create a BeautifulSoup object from the HTML content
soup = BeautifulSoup(response.content, 'html.parser')
# Find the first instance of a movie title
title_element = soup.find('td', {'class': 'titleColumn'})
# Extract the text content of the title element
title = title_element.find('a').text
print(title)
In this code, we first make a request to the IMDb Top 250 page and create a BeautifulSoup object from the HTML content.
We then use the find() function to search for the first occurrence of an HTML element with the tag name ‘td’ and the class name ‘titleColumn’.
This element contains the movie title, so we use the find() function again to search for the first occurrence of an HTML element with the tag name ‘a’ that is a descendant of the title element. Finally, we extract the text content of the a tag using the text attribute.
The find() function can also be used to search for elements based on other attributes, such as the id attribute. Here’s an example:
# Find the first instance of an HTML element with the id 'my_element'
element = soup.find(id='my_element')
Overall, the find() function is a powerful and flexible tool for searching for specific HTML elements within a document using a wide range of search criteria.
2-b) Retrieving the previous structure with BeautifulSoup
Now that we have seen how the find function works, we can get all the HTML elements with the class style_Collection__Dhplh identified in section 1.
From there, we will get all the links, that will lead us to the collection pages.
Code for the part 1-a)
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:95.0) Gecko/20100101 Firefox/95.0",
"Accept-Language": "fr,fr-FR;q=0.8,en-US;q=0.5,en;q=0.3",
"Content-Type": "application/x-www-form-urlencoded;charset=UTF-8"
}
def url_to_soup(url):
rez = requests.get(url, headers=headers, cookies=None)
if rez.status_code != 200:
raise Exception(f"Query failed for url : {url}")
return BeautifulSoup(rez.text, 'html.parser')
soup = url_to_soup("https://www.svgrepo.com/collections/all/2")
collections = soup.find_all(class_="style_Collection__Dhplh")
collection_link = ["https://www.svgrepo.com" + e["href"] for e in collections[0].find_all("a", href=True)][0]
# Results : collection_link = 'https://www.svgrepo.com/collection/start-universal-tiny-oval-icons/'
Once the url for a collection is found, we can follow it and find all the img elements, as seen while inspecting the page in section 1.
Code for the part 1-b)
soup = url_to_soup("https://www.svgrepo.com/collection/start-universal-tiny-oval-icons/1")
class_name = "style_Node__7ZTBP"
collections = soup.find_all(class_=class_name)
svg_links = ["https://www.svgrepo.com" + e.find("img")["src"] for e in collections]
"""
svg_links = ['https://www.svgrepo.com/show/506720/logout.svg',
'https://www.svgrepo.com/show/506721/menu-horizontal.svg',
'https://www.svgrepo.com/show/506722/minus.svg',
'https://www.svgrepo.com/show/506723/menu-vertical.svg',
'https://www.svgrepo.com/show/506724/lock.svg',
'https://www.svgrepo.com/show/506725/login.svg',
'https://www.svgrepo.com/show/506726/notification-stop.svg',
'https://www.svgrepo.com/show/506727/mute.svg', ...]
"""
You should be able to easily adapt this part of the post to you use case.
The next step will be to industrialize the scrapping.
2-c) Making it a scrapper
We have defined the main bricks in the previous section.
We just need to combine these two blocks, so that we can cover all collections and all SVGs on the website.
class SVGScrapper():
def __init__(self, save_file_path: str):
self.save_file_path = save_file_path
self.error_log = "./error.log"
self.failed_collections = list()
def main(self):
start_index = 1
max_page = 123
for i in range(start_index, max_page + 1):
print(f"Handling page {i}")
collection_links = self.parse_listing_page(i)
for link in collection_links:
print(f"Collection {link}")
try:
time.sleep(0.1)
svg_links = self.parse_collection_pages(link)
with open(self.save_file_path, "a") as f:
f.write("\n".join(svg_links))
except Exception as e:
self.failed_collections.append(link)
with open(self.save_file_path, "a") as f:
f.write(link + "\n")
def parse_listing_page(self, index):
soup = url_to_soup(f"https://www.svgrepo.com/collections/all/{index}")
collections = soup.find_all(class_="style_Collection__Dhplh")
collection_links = ["https://www.svgrepo.com" + e.find("a", href=True)["href"]
for e in collections]
return collection_links
def parse_collection_pages(self, link):
soup = url_to_soup(link)
max_page = int(soup.find(class_="style_pagingCarrier__uf8b7").text[-1])
svg_links = list()
for i in range(1, max_page + 1):
print(f"Collection page {i}")
soup = url_to_soup(link + f"/{i}")
class_name = "style_Node__7ZTBP"
collections = soup.find_all(class_=class_name)
svg_links += ["https://www.svgrepo.com" + e.find("img")["src"] for e in collections]
return svg_links
A few elements to notice :
- We need to detect the number of pages to scrap, this is why we have
max_page = int(soup.find(class_="style_pagingCarrier__uf8b7").text[-1])on the collection page. - It is interesting to maintain an error log and to an index log, in order to know where to resume when a failure happens
2-d) Running the image collections work
The previous scrapper did only part of the work. It collected the links of the images. We need to do the last part : the download.
It can make sense to split the work as downloading large file can be time consuming and prone to network errors.
To download the list of urls, we will use a wget command. It has everything that we need.
wget -i my_url.txt -w 0.1 --random-wait -x
What do these options do ?
- i: use a file to define the url to download
- w: wait between download (in seconds)
- random-wait: create variations +/- 50%
- x: store svg in directories, better as files can have similar names
Conclusion
In this tutorial, we’ve seen how to scrape a website in very little time using Python and BeautifulSoup.
By understanding the structure of the website and using powerful tools like BeautifulSoup selectors, we can easily extract data from websites and automate the process of data collection.
I hope this tutorial has been helpful, and that you’ll explore the world of web scraping further in your own projects!