
Can we predict the future of llms with another ml community ?
You want to know what will come next in the LLM world. I may have an answer for you based on what happen with Dall-E and STable Diffusion.
The Parallel with Dall-e
If you look back about 1.5 years ago and you wanted to use these latest txt-2-img models. You did not have so many choices : Dall-e, Midjourney or Stable diffusion.
After trying some of them, the visual results were striking :
With Dall-e, you could clearly see you had a better image quality. As Dall-e was a commercial product, being actively developed. It would obviously win in the long term, right ?
However, in between, the open source developers started to play with Stable diffusion model and train lora on custom dataset. These finetunings allowed to exceed the perceived state of the art image quality but also to represent some concept that the base model could not express.

With the more recent releases of Stable-diffusion-XL, the gap between proprietary and open-source models remains limited.

The main limitation today blocking a larger usage of Stable diffusion (SD) is the GPU requirement. When running on CPU, it runs 10 times slower and becomes less usable than any other cloud alternative.
I thought we would talk about LLM
Today, in the LLM landscape, we are not so far away from the stable diffusion use case from 1.5 years ago.
- 2 big proprietary player : ChatGPT and Claude
- Many smaller open source initiatives : Llama, Mistral and other
From a user perspective, we have the same statements : a cloud offer is easier to use, but when the proprietary models fail on your task, you may want to finetune an open source model or use a Retrieval Augmented Generation.
Where should I have a look then ?
r/localllama
How to better introduce this subreddit than with this quote from Karpathy ?
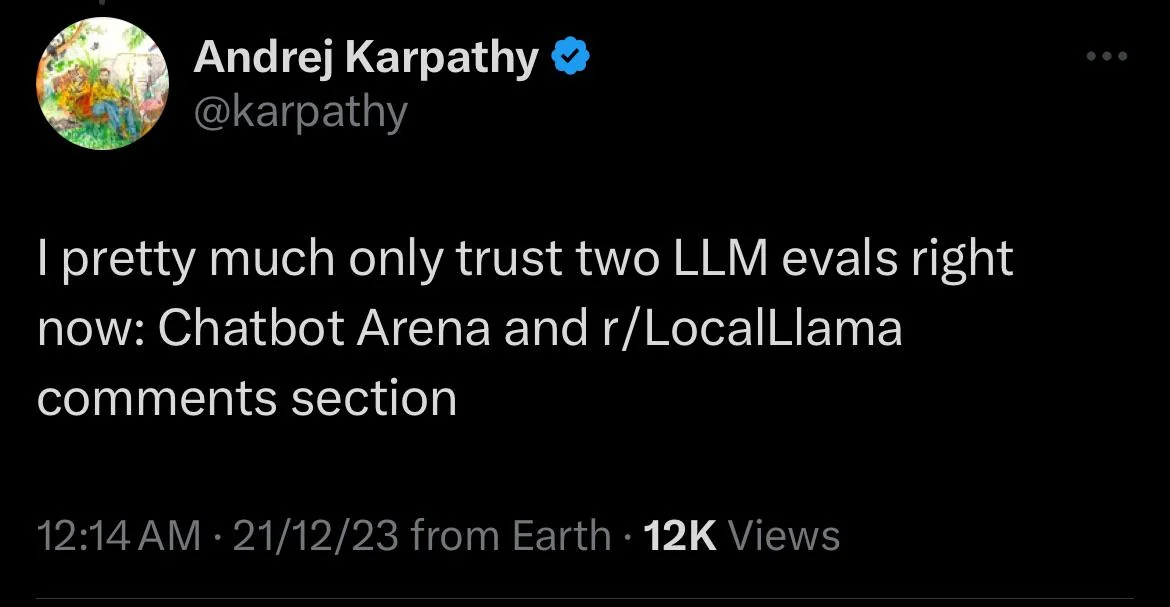
This subreddit focuses on harnessing the open source LLMs. A key area where the interaction is fruit ful is on LLM evaluation.
Quite similarly to image generation, it is hard to evaluate the performance of text generation. And thus feedback from many professional in the field is really helpful.
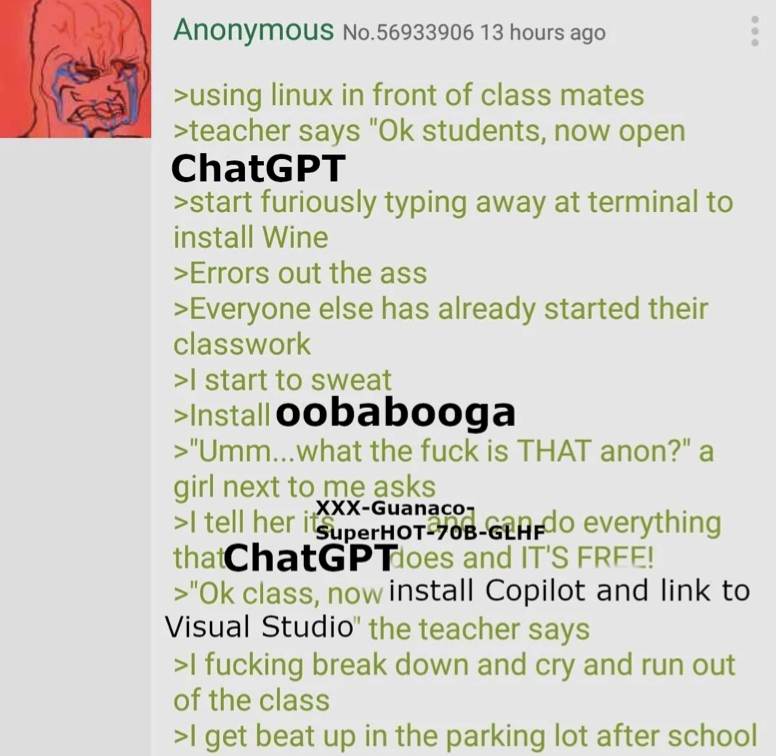
And things can get technical really quickly, even for machine learning practitioners. Just look at the next screenshot and tell me if the user is joking or not.

I assure you this is not satire and an actual feedback from someone who tested many models.
What to expect from this subreddit ?
- Practitioner advices on RAG and finetuning best practices
- Benchmarks to compare models
- Tests in production performance
Interesting links to discover:
Huggingface model repository
A lot of people are experimenting with models thanks to huggingface. But isolated experiments wouldn’t bring as much as the model repository that Huggingface is today.
If we come back to the parallel of txt-2-img, finetuning on custom dataset have been used to learn how to generate a better base model. You could find pretty advanced discussions on the model merging topic on reddit 1, 2
You can find a similar trend on HuggingFace for the LLM. Mistral fine-tuned on ORCA, PLATYPUS or others.
It is impossible to summarize what happens there. But one reference I can mention is TheBloke. This person focus on making available all quantizations of open-source models. This enables everyone to run large models on commodity hardware like your laptop.
Interesting links to discover:
Oogabooga
Another parallel with the SD community, having an environment to easily run your model made everything easier.
To run stable diffusion, the reference is Automatic1111, named after its author. It reached 115k+ stars on Github. The tool enabled the access to technology to a large audience. With more people, more dataset could be collected, more experiments on model could be learned, etc.
Another repo is actually reproducing the same approach Oobabooga. It is still behind in term of maturity but also has an active community (30k stars).
This UI allows you to run any desired model with quantization, cpu or gpu, update prompt templates and even finetune a model.
Interesting links to discover:
Additional resources
The field is growing super fast and it is difficult to put everything in labeled boxes.
For those interested in specific topics like finetuning, I added a list of useful resources
Wrap-up
You want to know what will come next in the LLM world.
Have a look in the Open Source world. And you will need time to ingest everything, but it’s best to start now.