Building a ui for a generative ai app part 1
Introduction
In this previous post, I presented how to generate videos based on stable diffusion.
In this post, I wanted to present the UI used to simply build the videos, and the challenges met while building it.
Too Long Didn’t Read :
An example of the video story generated.
@truebookwisdom The myth of the four suns #aztec #myth #god #story ♬ original sound - truebookwisdom
If you want to know how I build these videos, read the rest ;)
General overview
The goal of the app would be to create small video stories based on a text.
The UI should help to make the creation faster, but not necessarily make everything possible.
A diagram of the logic was described in the previous post :
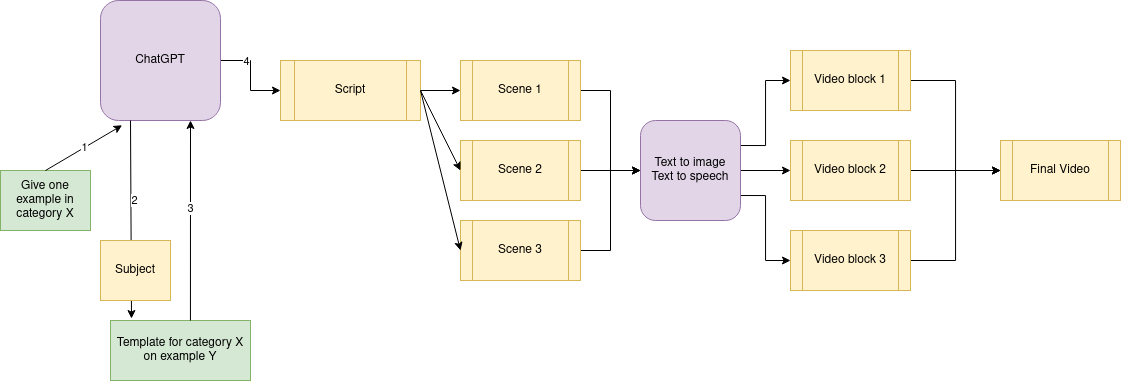
In short, ChatGPT generates a story. Each sentence is translated to an image with Stable Diffusion. And finally txt2speech adds the narration voice.
Idea 1 : the brute force approach
> The overview of the logic
- We start with a large block of text that we will split in 10 sentences.
- Each sentence will be represented by 1 image
- For each sentence, create 15 images to choose from (with a txt2img model like Stable Diffusion)
- A UI allows me to pick the best image for each scene
- Finally all images and audio are combined into the video
> Let’s look at the UI
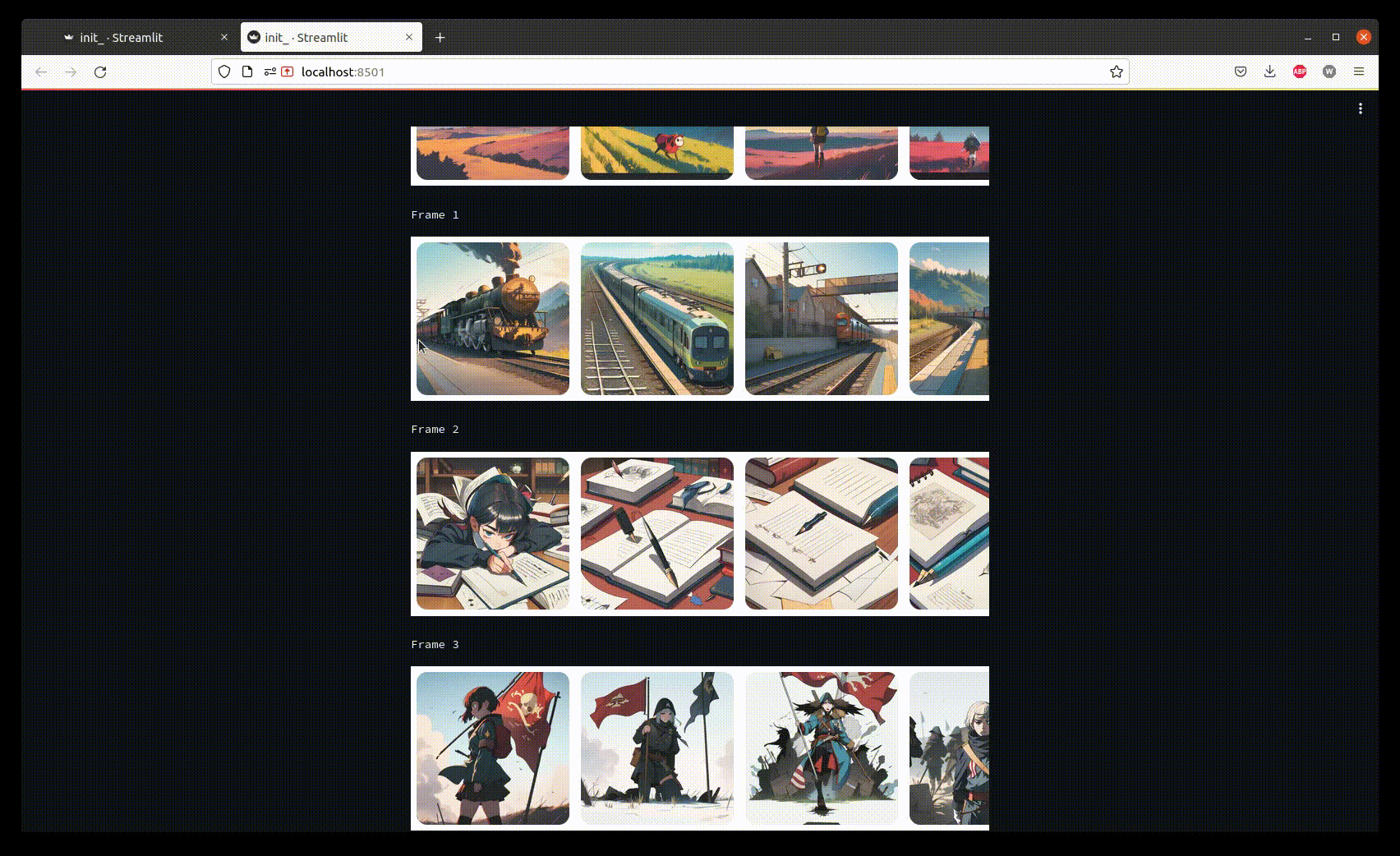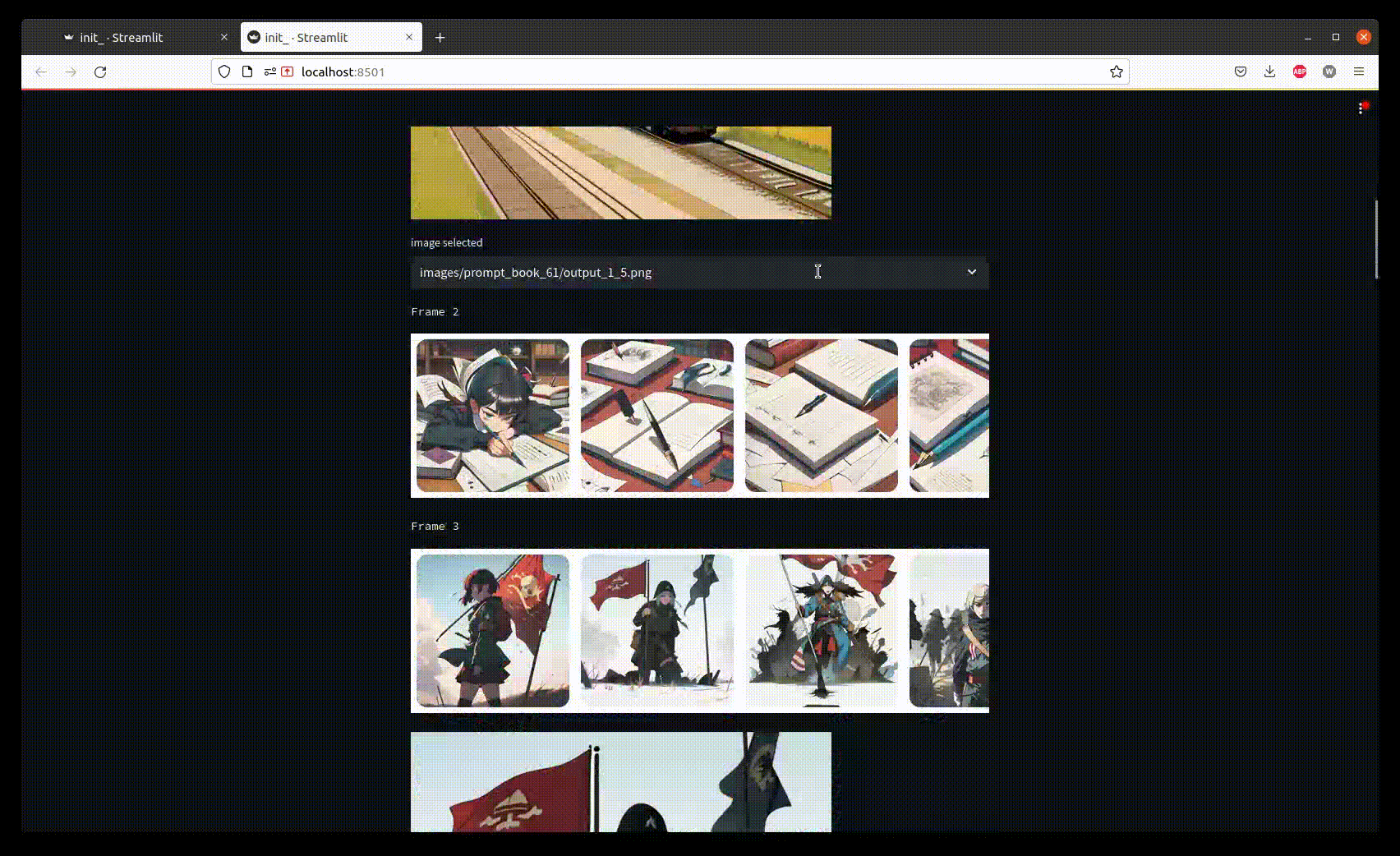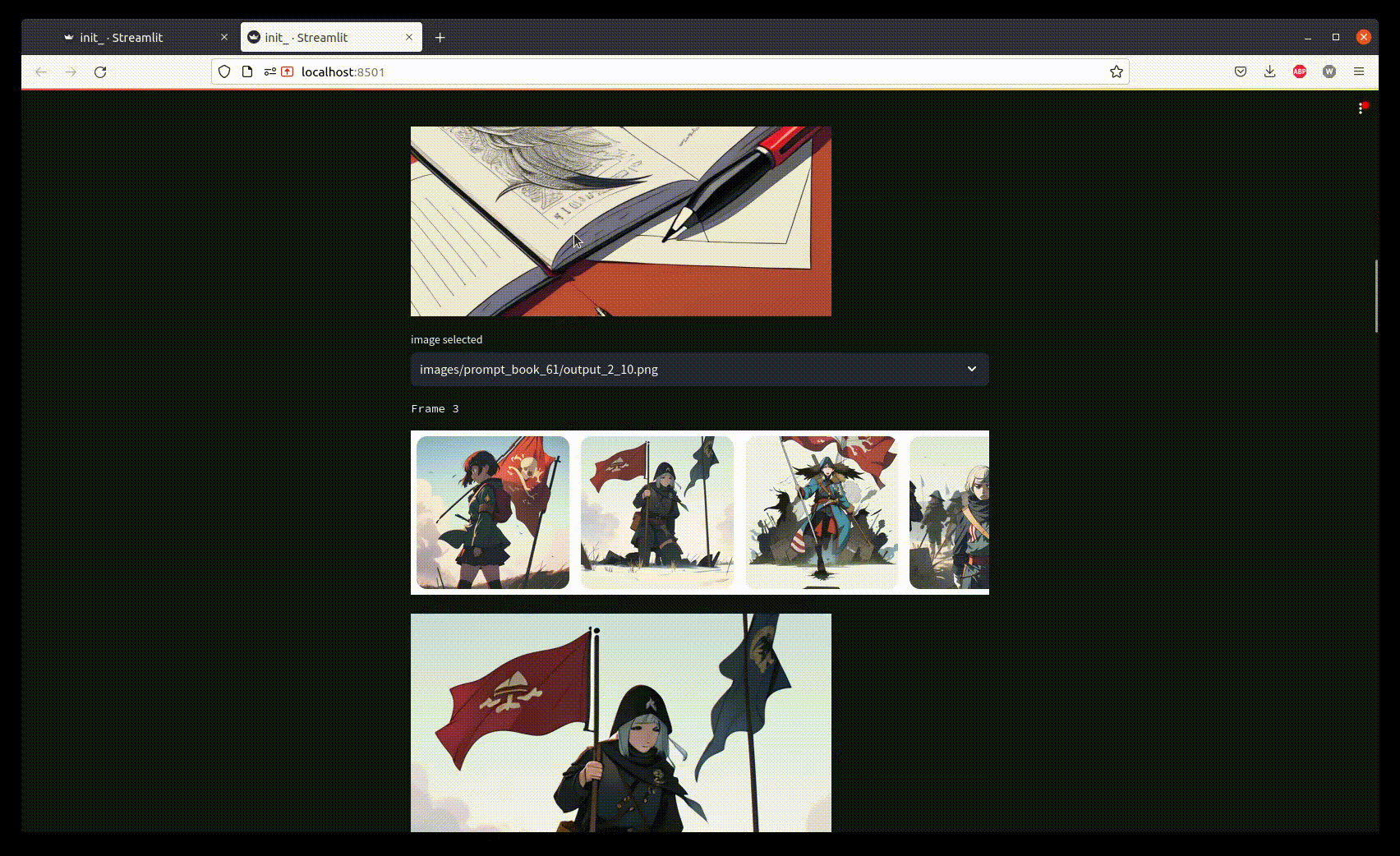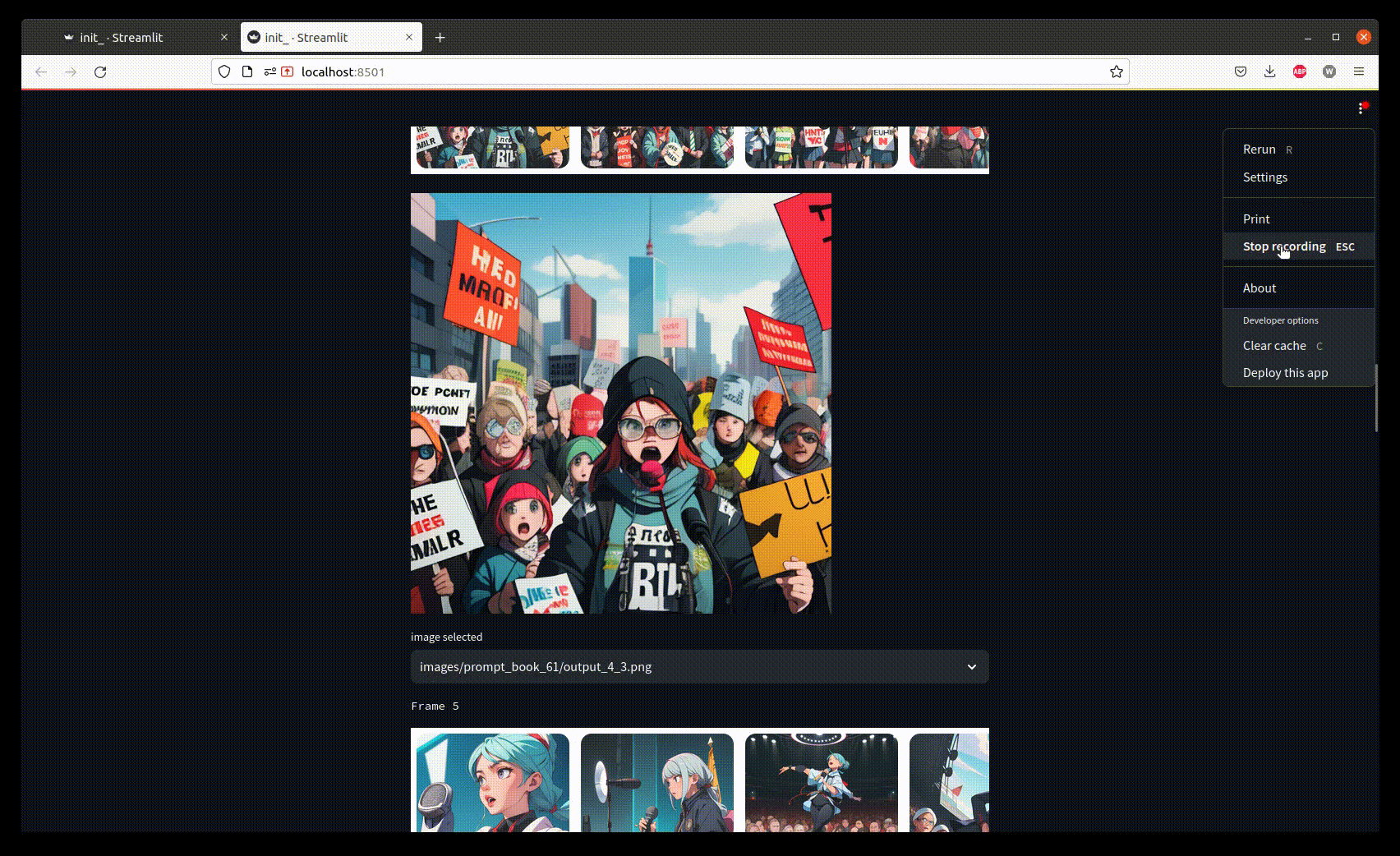
Once the generation process is finished, we only need to select good images corresponding to the story.
> Why this approach :
- Depending on your hardware, you can wait a rather long time to get 15 images generated for a prompt
- Also, txt2img technology is not perfect, there is sometimes obvious generation artifact that can ruin an image value (see example)
> A focus on the failure modes : why we need more than 1 image per sentence
Often SD1.5 models struggle on small details like hands, arms or even … glasses.

Here the count is not right.
Idea 2 : the creative interface
After working with the first approach for some weeks, I realised its limitations : all stories started to look the same and needed some manual editing.
As I was using ChatGPT to suggest both the content and the prompts, I was limited by what it could generate.
Additional controls were thus needed in the UI.
> Overview of the logic :
- Same structure as Idea 1
- I can edit each prompt if i’m unhappy with it
- Once done, I click a “generate” button, and it produces the video
In this video, images have already been generated based on the input story. And only one frame needs a change in the prompt. Finally, the video is finally combined with the final generate button.
> The UI in details
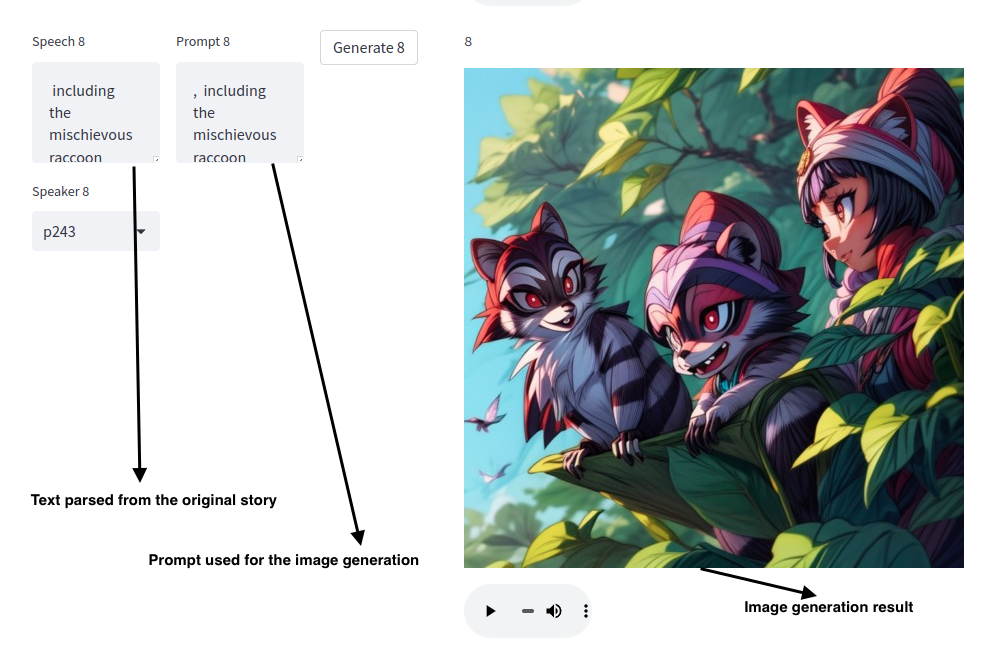
The UI descibes how the story is broken down in smaller blocks. Each block correspond to an image. If the prompt for this image does not provide a satisfactory image. One can change the prompt.
However we lose the ability to choose among a list of 10 images as everything is synchronous.
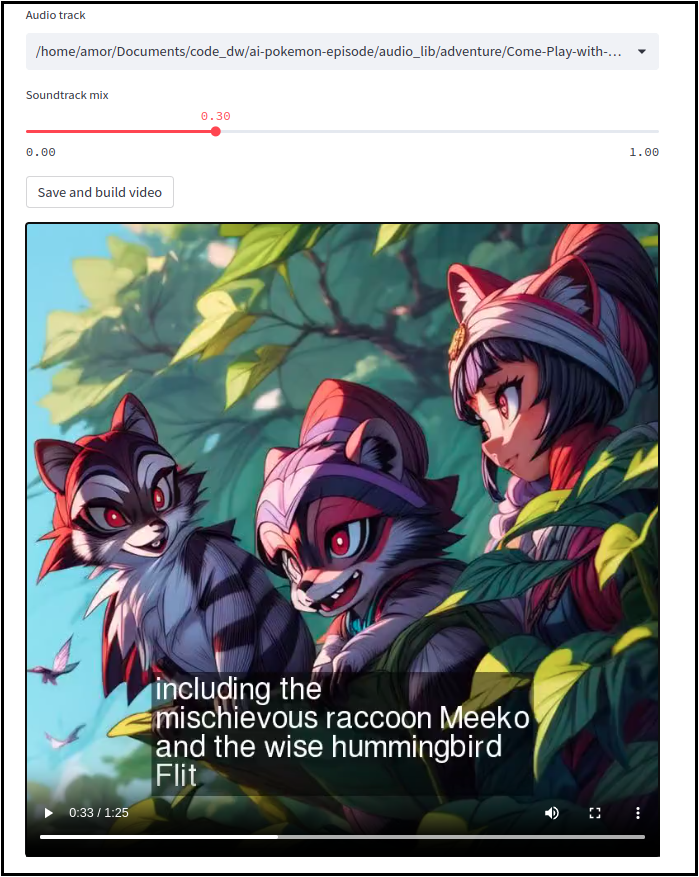
It is possible to preview the final video once all the images are generated.
> Example of video generated
In this example, I took the story of the little mermaid outputed by ChatGPT and tuned the prompt for better visuals.
@truebookwisdom The original little Mermaid story #mermaid #disney #tale #sadstory #love #learn ♬ original sound - truebookwisdom
Idea 3 : Character generation helper UI
The previous UI change was beneficial to the overall quality of the videos, but much more time consuming.
So, I looked at how I could add automation into the generation process : by making character generation consistent
> Overview of the logic :
- We have the input story which is a large block of text
- I use a model from Spacy to detect multiple references of the same character in this story
- Characters are represented by a cluster of words
- Each cluster will get its own prompt
- When an element of a cluster is found in a sentence, we add all the prompt words attached to this cluster
- This mechanism helps to automatically fill the prompts for each sentence
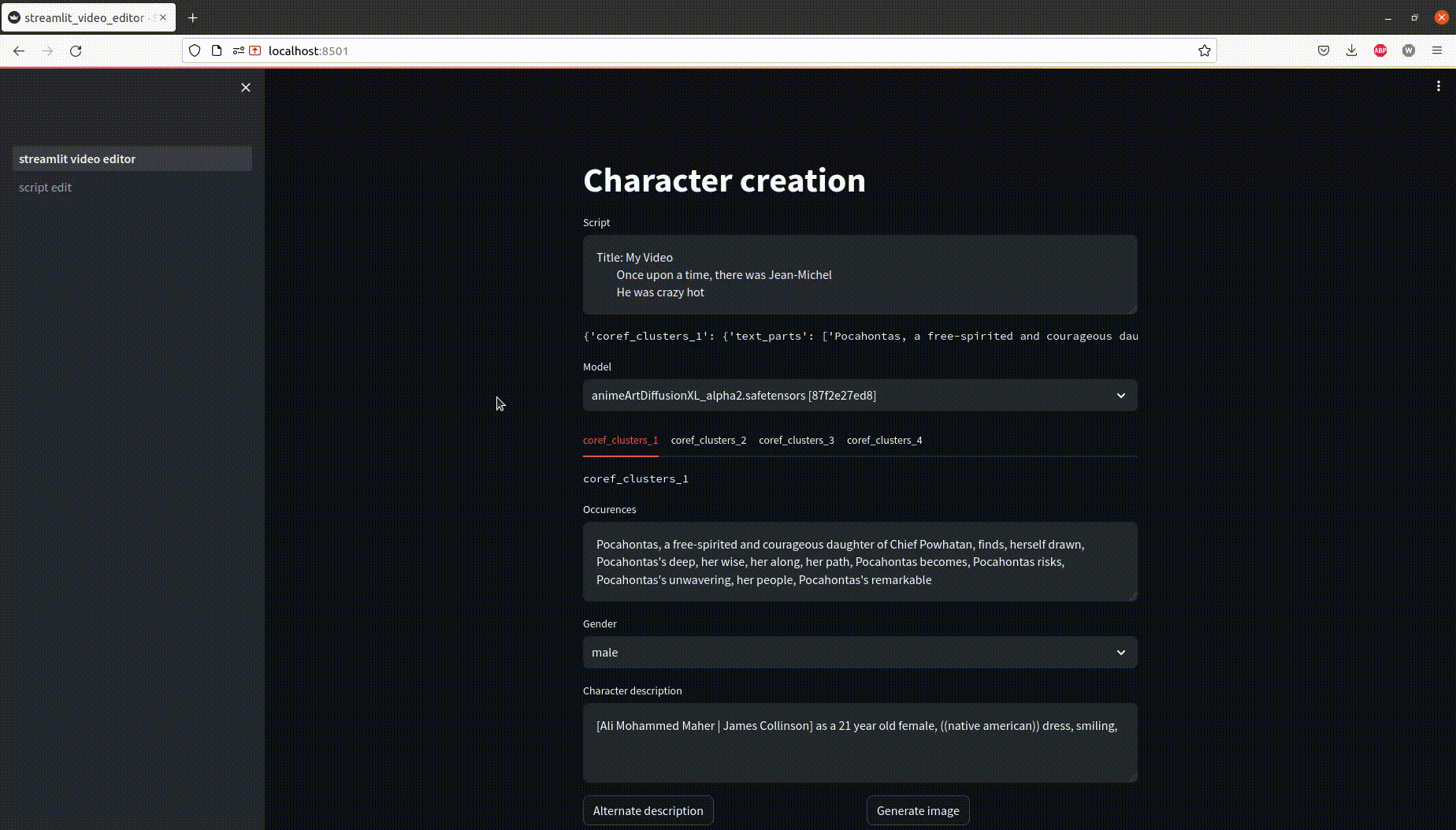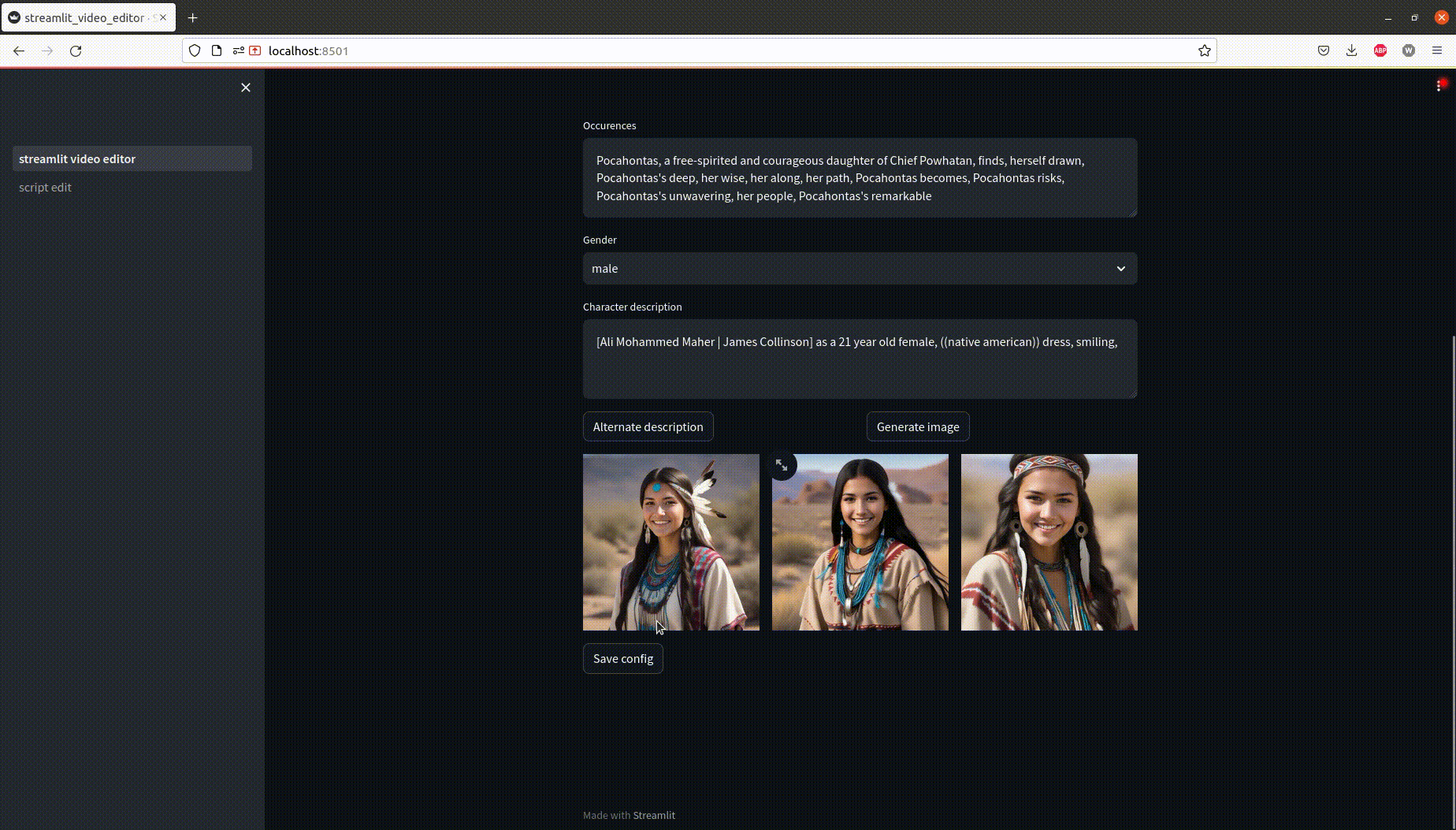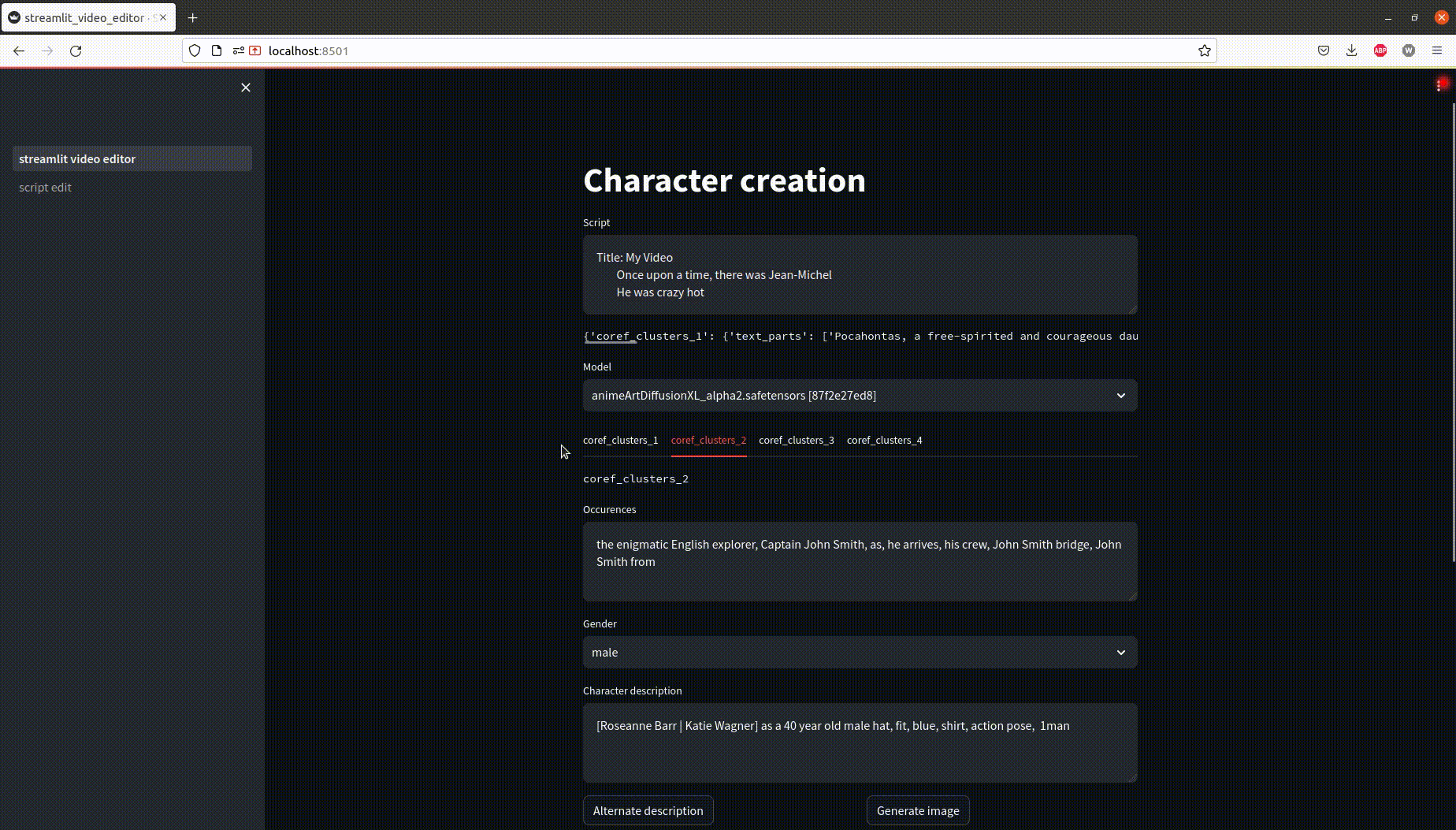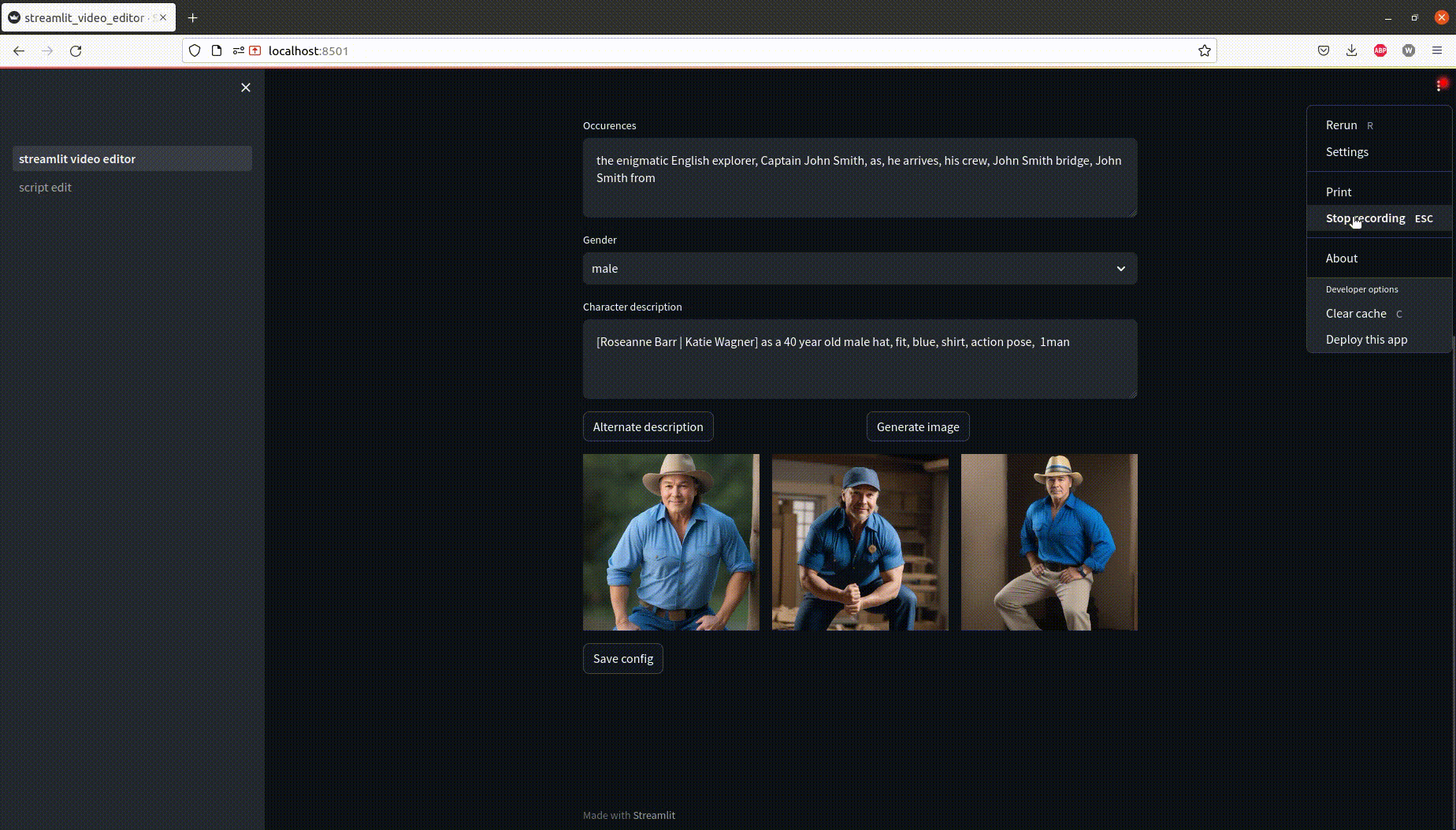
In this example, two characters are identified and assigned a prompt to get a consistent visual identity.
> Focus on the UI
The UI achieves different purposes :
- Manually identify what is cluster is about with the words of the cluster
- Define the prompt words for the cluster
- Preview how a prompt will consistently generate a character
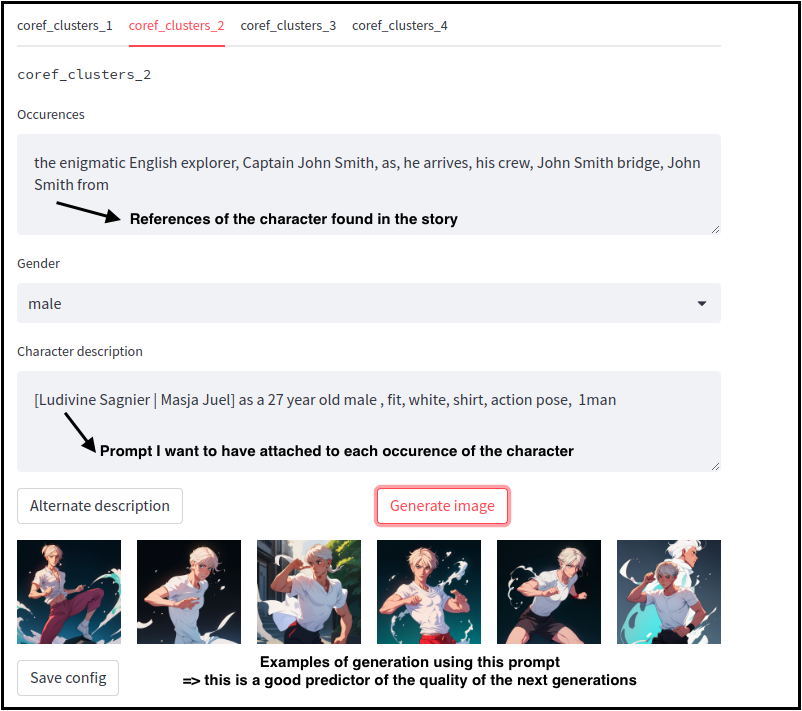
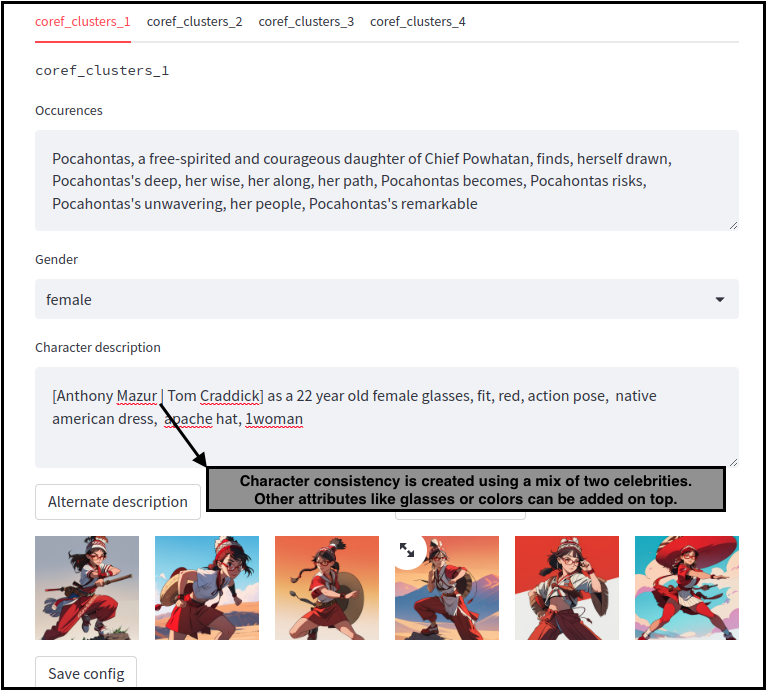
Back to the original UI, prompts will have the right character description magically filled
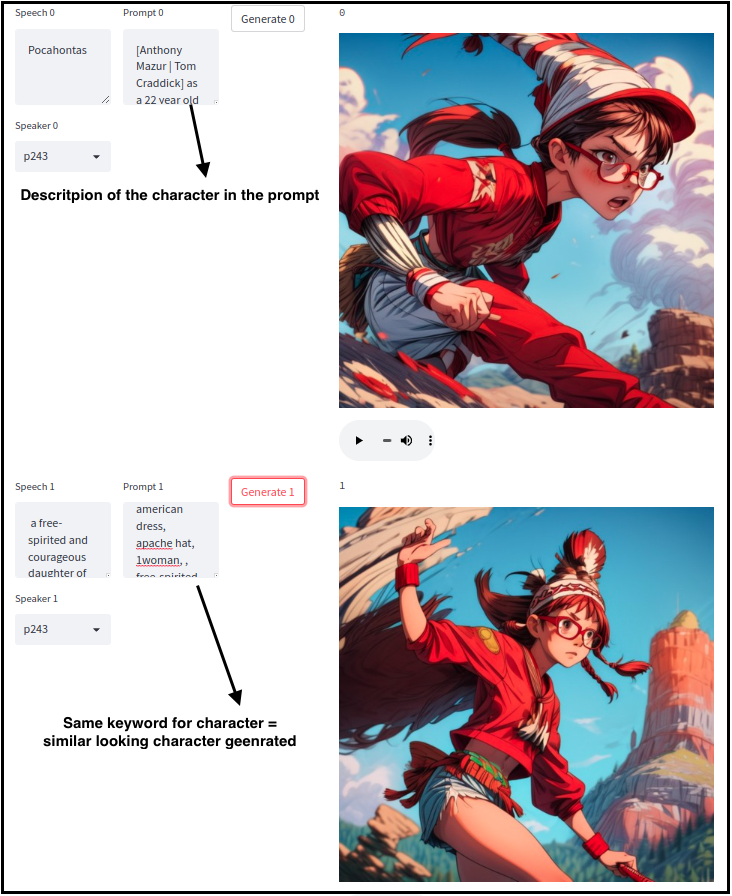
> An example video
In that video, 2 characters were used :
- Siegfried : identified by grey hair, a certain face and an armor
- The dragon : only a simple prompt was used for it : “dark dragon”
@truebookwisdom The tale of Siegfried - Part2 #knight #tale #dragon ♬ original sound - truebookwisdom
Conclusion
With this tooling, I was able to turn a txt2img technology to a video creation tool.
A lot of additional development could be made like :