
A personal ai language teacher
Introduction
In this previous post, we have seen we can have a video agent answering to a written chat. A perfect match for Twitch.
But we could go further in many direction :
- Allow a personal conversation with the bot
- Scale the architecture to have 10’s of conversation in parallel
- Handle multiple personas and languages
But for what purpose ? Personally I’ve always wanted to improve my German but found it hard to do it. So this is gonna be my target in this post.
Test the app !
Choose a language. You can interact orally like you would with a language teacher.
An audio or video response is generated based on what you said, in the target language.
And you get the transcript of the conversation in the chat to be able to better understand .
You want to discover more ?
Have a try on the HuggingFace space !
An example of conversation
By using the text comprehension level of ChatGPT-3.5, I could have a computer related conversation in German with very technical words.
How to read the next screenshot :
- On the right, the transcript of my oral conversation
- On the left, the response from the bot and the audio speech generated
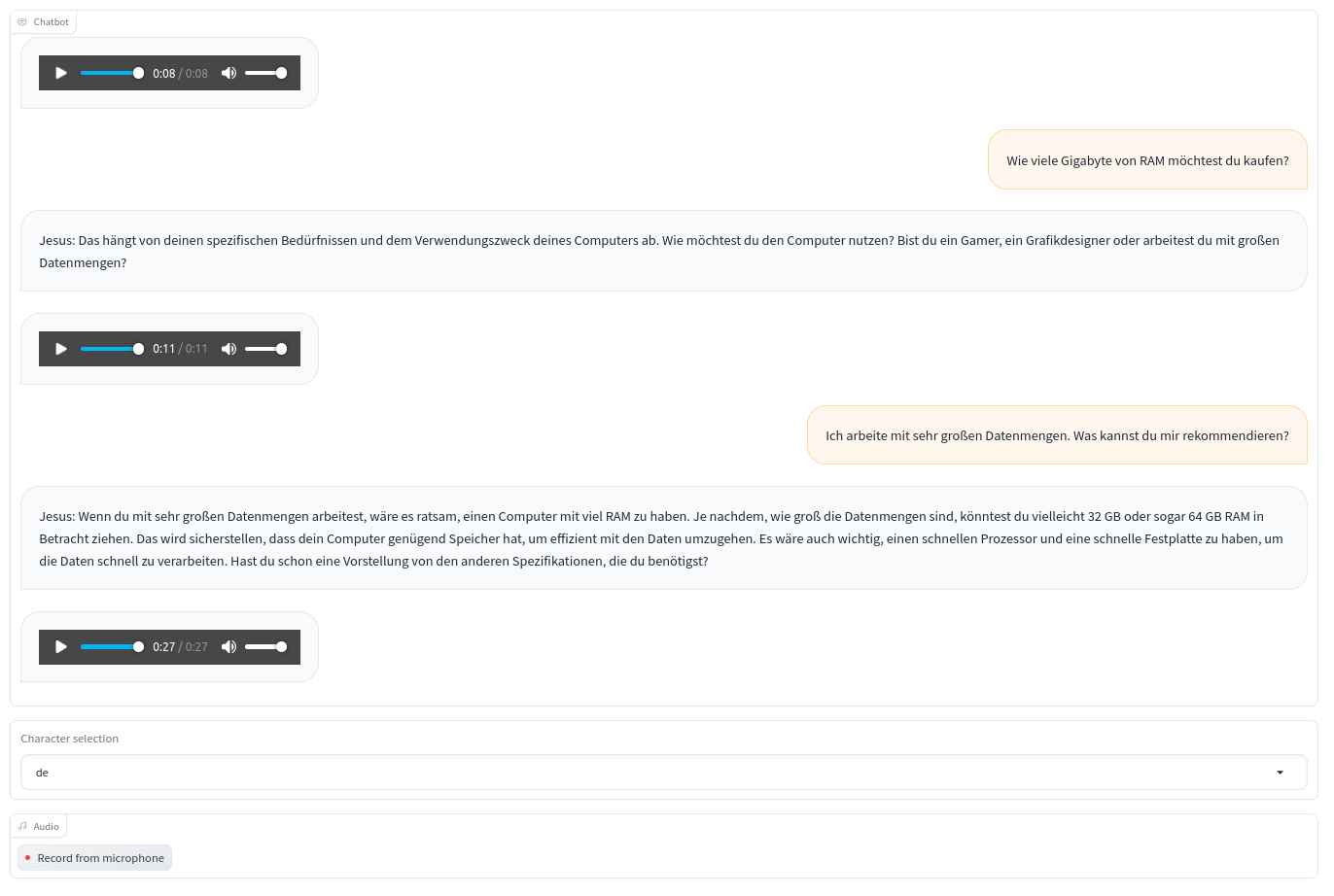
For less enclined in Goethe language, here is an approximate translation :
- User : How many Go of RAM should you buy ?
- Bot : It depends on the use case, how do you want to use your computer ? Are you a gamer or …?
- User : I work with very large data workload. What could you recommand me ?
- Bot : … I would recommend 64 Go of RAM …
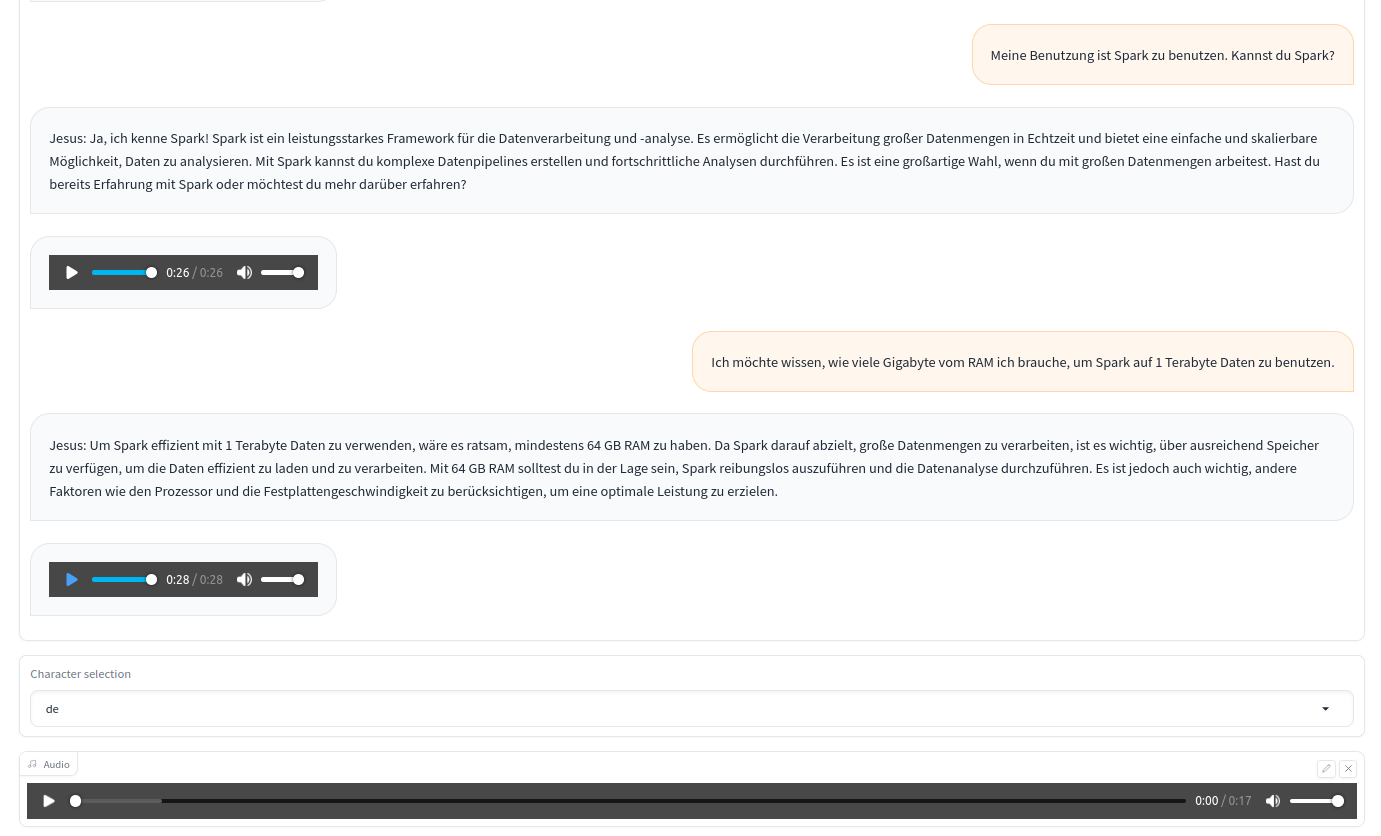
Personally, the learning came from :
- hearing the sentences and being able to read them afterward.
- speaking out loud my sentences
- the conversation was free-form and much funnier than ‘the cat is blue’ type of conversation
How does it work ? The ML ingredients
The system works with the following elements :
- Whisper for transcription
- ChatGPT with a prompt template based on the language chosen
- Text to speech
- Wav2Lip to generate the video
In this example, Whisper and ChatGPT use the OpenAI endpoint to limit the VRAM usage on the local machine.
Text to speech uses an updated Silero server repository. This offers multi lingual support without being too slow or heavy.
Wav2Lip uses the same repository as the previous post.
How does it work ? System architecture
The system can be summarized with the following diagram :
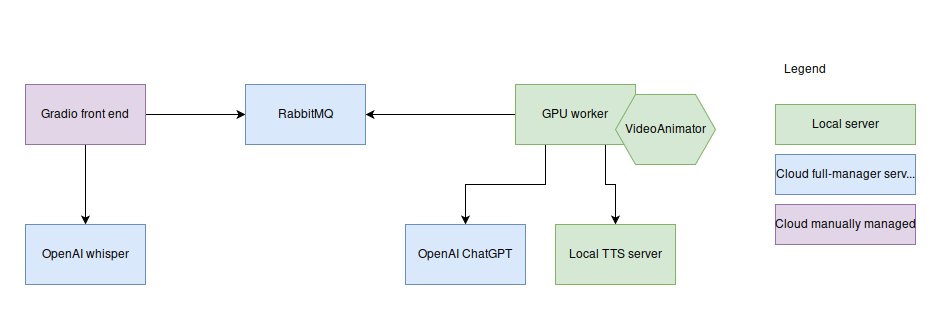
The components of the service as a whole can be on 3 types of plateforms :
- Local : a computer with low reliability but cheap to own for a long duration
- Cloud manually setup : a vm or a server deployed with a cloud manager service
- Cloud fully managed service : Saas like, almost no configuration is required
Why not all cloud ? This is specific to this project. In order to be able to deploy it without needing a loan, some tradeoffs were needed :
- GPU are very expensive on the cloud but kind of cheap at home
- But some GPU service are cheap : like openAI ChatGPT
- Some cloud services are also free in their most basic service tier. But you need to adapt in order to remain under the usage limits
Why do you use queues ?
First question : why would you want to use a queue system for this use case ?
My guesses were the following :
- GPU ressources will be the scarcest
- Processing time can hugely vary from a few seconds up to a minute depending on the response length
- 1 Gpu may serve several users at the same time
Using a queue has other advantages compared to an http service alternative :
- No need to have a service with a (costly) load balancer
- A publicly accessible URL might also be more expensive to get
So handling GPU requests in a queue makes sense as it is cheap and still allow scaling to multiple client.
Cloud RabbitMQ and its optimization
In order to have a scalable queue, one has many different options like AWS SQS. But I end up testing CloudAMQP because of the free plan and the RabbitMQ interface.
Is rabbitmq important in the plan ? Yes it is. In fact, in the previous design. The GPU workers all share the same input queue but each client might need it own reply channel. This is an issue for cloud ressource usage intensity.
But with RabbitMQ, there is a feature to escape this issue Direct reply-to. It allows to escape this precise limitation of the design.
Implementation with the pika library
After a very long crawl across the internet, I found the way to implement it with a consumer pattern rather than pure callback. This allows a better integration with the web server.
import pika
def handle(channel, method, properties, body):
message = body.decode()
print("received:", message)
connection_ = pika.BlockingConnection()
channel_ = connection_.channel()
channel_.queue_declare(queue="test")
channel_out = connection_.channel()
with connection_, channel_, channel_out:
# 1 - The client prepares the reply channel and send its message
message = "hello"
next(channel_.consume(queue="amq.rabbitmq.reply-to", auto_ack=True,
inactivity_timeout=1))
channel_.basic_publish(
exchange="", routing_key="test", body=message.encode(),
properties=pika.BasicProperties(reply_to="amq.rabbitmq.reply-to"))
print("sent:", message)
# 2 - Server part with the reply-to
(method, properties, body) = channel_out.basic_get(queue="test")
channel_out.basic_publish(exchange="", routing_key=properties.reply_to, body="Pouet")
channel_out.basic_ack(delivery_tag=method.delivery_tag)
# 3 - The client listen to the reply-to and can get its answer
for (method, properties, body) in channel_.consume(queue="amq.rabbitmq.reply-to", auto_ack=True):
handle(channel_, method, properties, body)
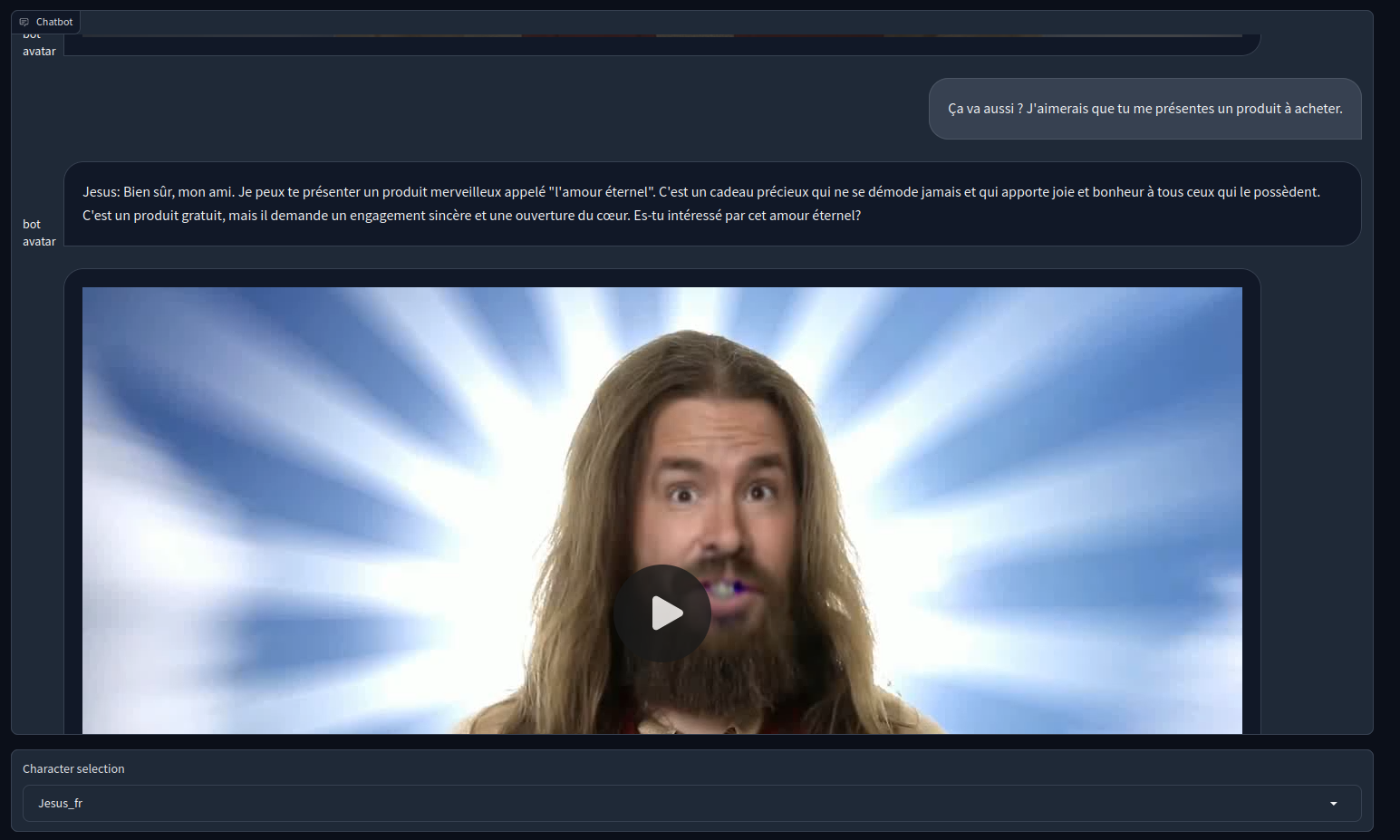
Variation : The bot answers with a video
One interesting thing with the Gradio chat implementation is that chat can be conducted by text, audio or video without large implementation changes.
Especially between audio and video, there is no need to change anything, only the path of the media file is needed.
An example of how to build the chat history object : the first item is the addition of the user request and the bot response. The second item is the video file response on the bot side only.
history += [(response.request, response.text_response), (None, (video_path,))]
Conclusion
- The ML bricks were easy to set up
- The Queue was the most difficult to set
- The latency remain high without a streaming connection with the language model